Bulk Cut and Run
UM Bioinformatics Core
2023-08-29
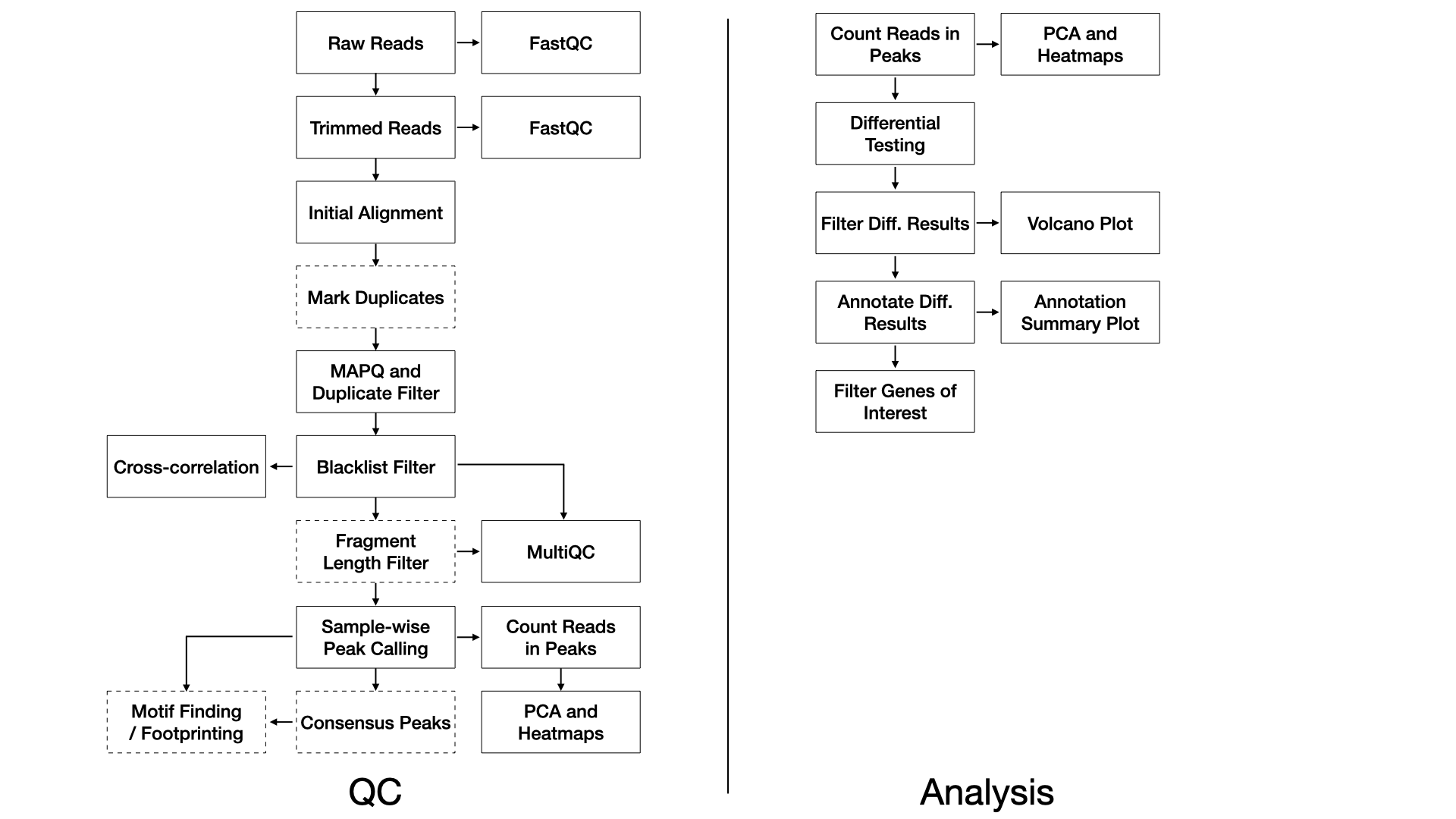
Methods
QC
We use FastQC (FastQC) (v0.11.8) to assess the overall quality of each sequenced sample.
We use trimmomatic (Bolger et al.,
2014) (v0.39) with the following paramters:
ILLUMINACLIP:{adapter_path}:2:15:4:4:true LEADING:20 TRAILING:20 SLIDINGWINDOW:4:15 MINLEN:25,
followed by kseq (Zhu et al.,
2019) to ensure read lengths of at least 50bp.
We align trimmed reads to the genome with Bowtie2 (Langmead and Salzberg, 2012) (v2.3.4.1) using
default parameters with the exception of the following flags:
--dovetail
Duplicate reads may be are marked with Picard (Picard) (v2.20.2).
Alignments are filtered with samtools (Li
et al., 2009) (v1.2) using the flags:
-F4 -F8 -f3 -q10 -F1024.
Alignments completely overlapping blacklisted regions (ENCODE Blacklist Regions) are removed with bedtools (Quinlan and Hall, 2010) (v2.28.0).
Following the Cut and Run Tools pipeline (Zhu et al., 2019), reads are filtered for fragment lengths less than 120 bp.
Sample-wise peaks are called with macs2 (Zhang
et al., 2008) (v2.1.2) with flags:
-B --SPMR --format BAM --gsize {macs_genome}.
Optionally, consensus peaks for replicates are determined by mutual intersection of sample-wise peaks with bedops –intersect. Consensus peaks are then annotated with annotatr (Cavalcante and Sartor, 2017).
Optionally, motifs are determined with the MEME suite (Machanick and Bailey, 2011) (v5.1.1) followed by footprinting with CENTIPEDE (Pique-Regi et al., 2011) (v1.2) as in the Cut and Run Tools pipeline (Zhu et al., 2019).
Peaks over all samples are merged with bedops (Neph et al., 2012) (v2.4.36) for the purpose of principal component analysis and unsupervised clustering to assess the similarity of samples. Read cross-correlations within samples are plotted using phantompeakqualtools (Landt et al., 2012). MultiQC (Ewels et al., 2016) (v1.7) generates a report combining FastQC, trimming, alignment, and duplicate calling over all the samples. The software DeepTools is used to calculate coverage and IP efficiency plots (Ramírez et al., 2016) (v3.3.0).
Differential Testing
We use the edgeR R Bioconductor package (McCarthy et al., 2012) to identify regions of differential binding. For each sample, the number of reads in the merged peaks is counted for each sample, and a library size normalization factor is determined. With no replicates, we manually tune the BCV (biological coefficient of variance) parameter. We then fit each model using the glmFit function, and test each contrast with a likelihood ratio test. With replicates, the common, trended, and tagwise negative binomial dispersions are calculated. We then fit each model using the glmQLFit function, and test each contrast with an empirical Bayes quasi-likelihood F-test. The differential peaks are then annotated to genic and CpG island annotations using the annotatr R Bioconductor package (Cavalcante and Sartor, 2017).