Cell Type Annotation
UM Bioinformatics Core Workshop Team
2025-10-16
Workflow Overview
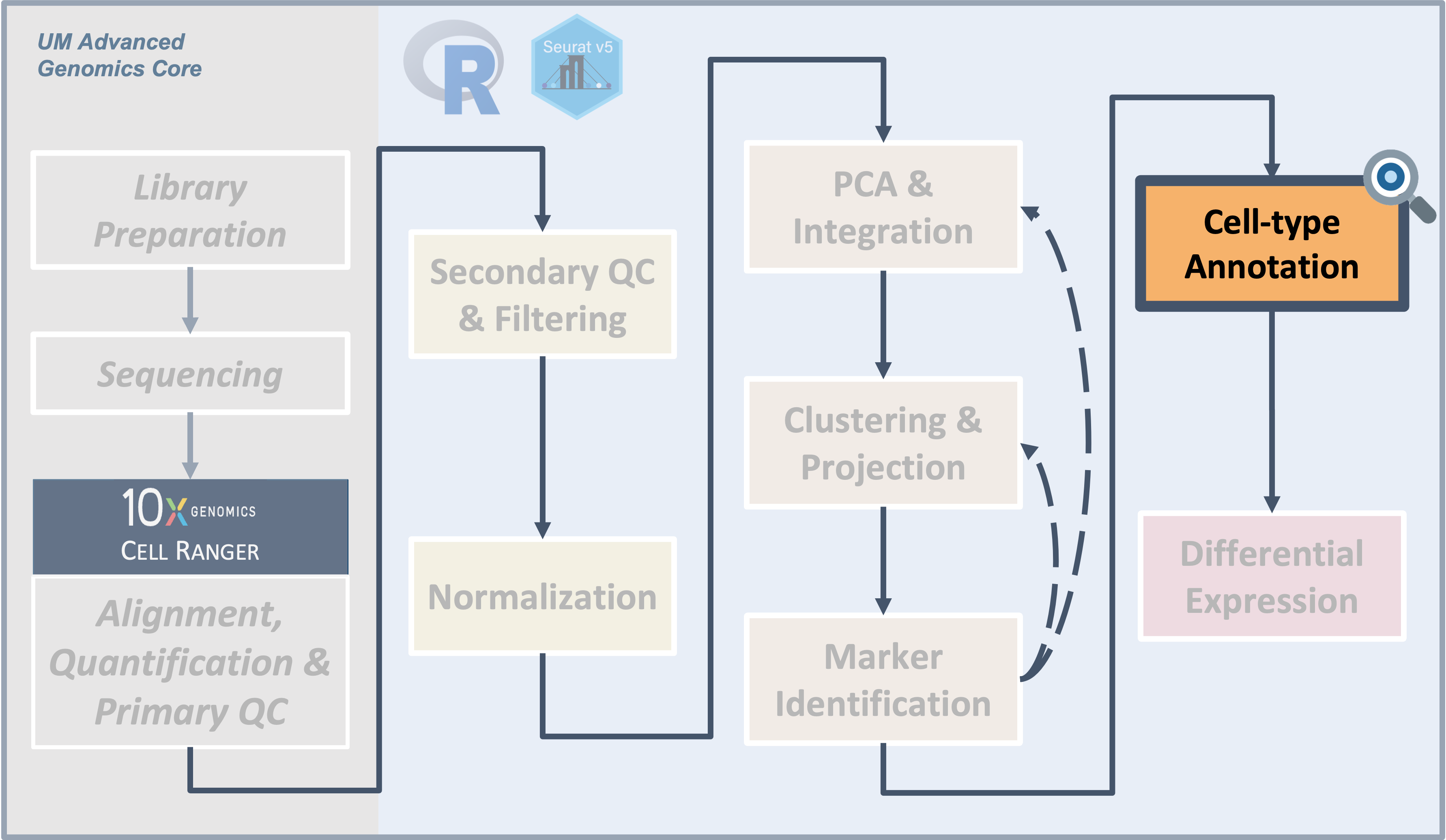
Introduction
|
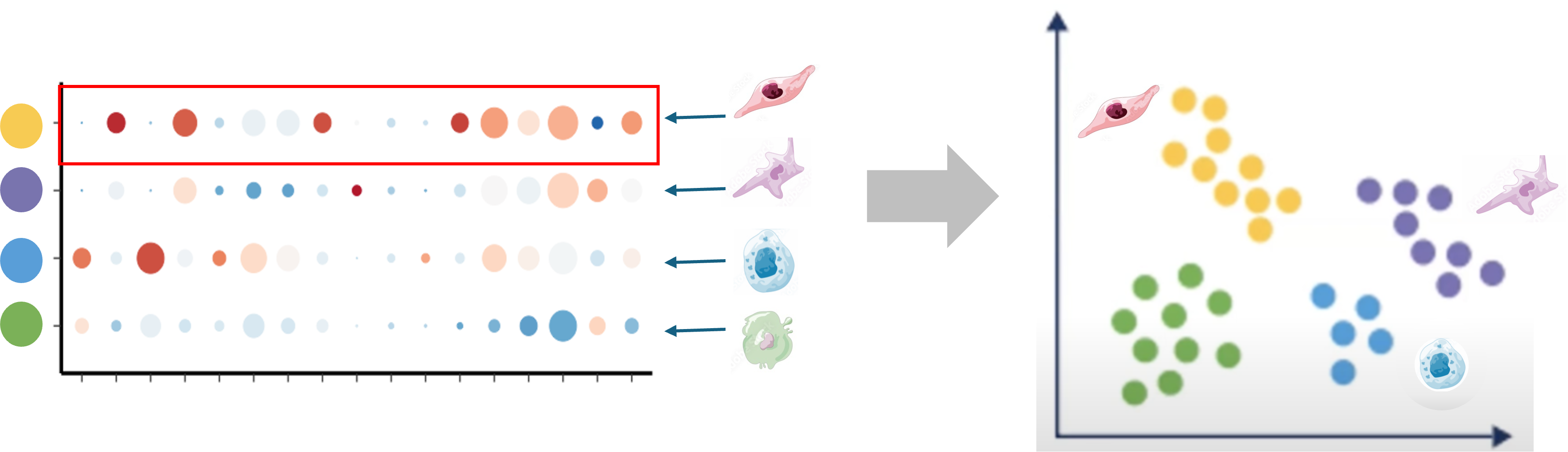
| Starting with clustered data, we can summarize and compare gene expression for known gene markers within each cluster, irrespective of sample or condition, to help label clusters with the appropriate cell-type or subtype. |
A frequent bottleneck in single-cell analysis is annotating the
algorithmicly generated clusters, as it requires bridging the gap
between the data and prior knowledge (source).
While generating markers for each cluster it important, it may or may
not be sufficient to assign cell-type or sub-type labels without
bringing in additional sources.
Objectives
- Understand the complexities of cell-type annotation
- Use
scCATCHcell-type predictions to annotate our clusters
Like the previous sections, the steps to assign cell-types to
clusters might require some iteration, can be very dataset dependent,
and often is more challenging for less characterized tissues.
Cell type predictions
Automated tools have the advantage of being able to compare between the expression patterns in our dataset and large numbers of reference datasets or databases at a scale that is not feasible to do manually.
There are many computational tools that aim to assign cell type labels for single-cell data. These methods generally fall into three categories:
- Marker based approaches that use gene sets drawn from the literature, including previous single-cell studies,
- Correlation based approaches that estimate the similarity between the cells or clusters in the input data and some reference data
- Machine learning approaches that include training on a single-cell reference atlas.
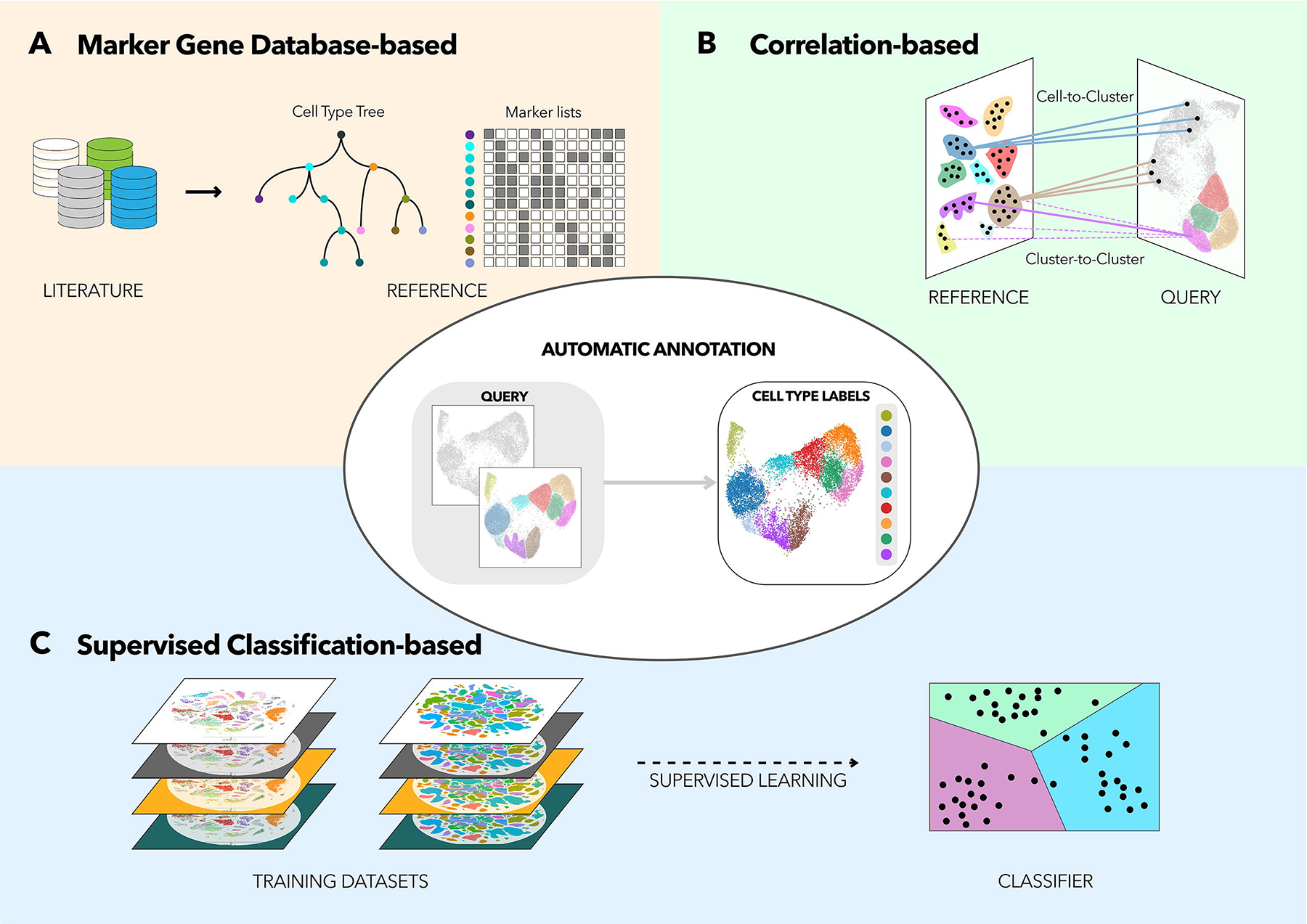
From Automated
methods for cell type annotation on scRNA-seq data
However, across any of these approaches the quality of the reference data (and reliability of the authors labels) and relevancy to your specific tissue/experiment (and the resolution of your biological question) is crucial. Additionally, it’s important to consider that rare or novel cell populations may not be present or well-characterized in available references and that even after filtering, some clusters might correspond to stressed or dying cells and not a particular cell-type or subtype. Therefore, any prediction should be reviewed and considered in the context both marker gene expression for the dataset and knowledge of the biological system and broader literature.
Some tools and references are available solely or primarily for human tissues (and not mouse or rat), particular for tissues other than PBMCs and the brain. For human data, if a relevant reference is available for your experiment, we would recommend trying Azimuth (created by authors of Seurat). 10x has a tutorial that includes example of using Azimuth, including a feature of the tool that allows for first pass of cell-type assignment of more common cell-types followed by identifying rarer populations.
Additional automated annotation resources
Automated cell-type annotation is an active area of research and development and many other tools and resources are available, including OSCA’s demonstration of the SingleR method, a Tutorial by Clarke et al. for cell-type annotations, and an entire chapter of the SC best practices book.Using scCATCH
A tool we often use for both mouse and human data cell-type predictions is called scCATCH which, per the author’s description in Shao et al (2020), annotates cell-types using a “tissue-specific cellular taxonomy reference database (CellMatch) and [an] evidence-based scoring (ES) protocol”. The CellMatch reference is compiled from CellMarker (Zhang et al., 2019b), MCA (Han et al., 2018), CancerSEA (Yuan et al., 2019), and the CD Marker Handbook and PMIDs for relevant literature are reported in the prediction results.
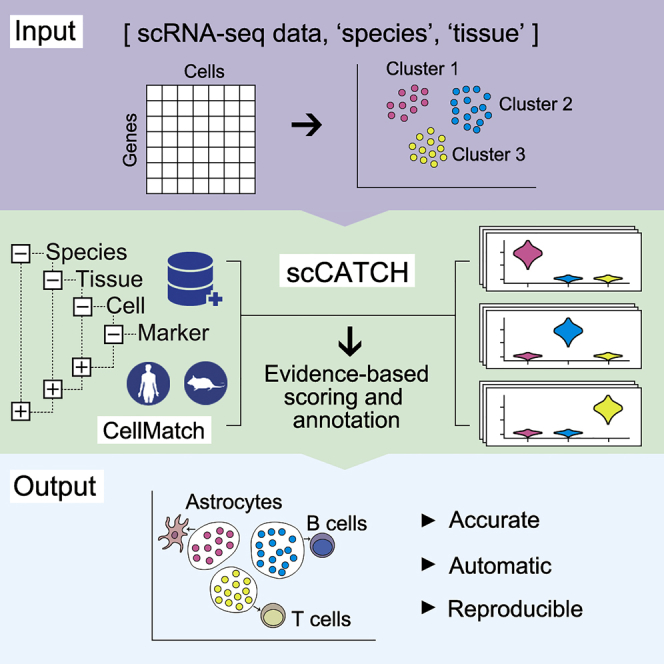
First, we need to load the scCATCH library. Then, we’ll double check
that we are using the expected resolution cluster results (this is
particularly important if we generated multiple resolutions in our
clustering steps), before creating a new object from our
counts data with createscCATCH() and adding
our marker genes to the scCATCCH object.
To increase the speed and accuracy of our predictions, we’ll create query of relevant tissues (which requires some prior knowledge of the experiment and using the scCATCH wiki to select tissues from the species) before we run the tool:
# =========================================================================
# Cell Type Annotation
# =========================================================================
# Load scCATCH
library(scCATCH)
# check that cell identities are set to expected resolution
all(Idents(geo_so) == geo_so$integrated.sct.rpca.clusters)[1] TRUE# -------------------------------------------------------------------------
# Annotate clusters using scCATCH
# create scCATCH object, using count data
geo_catch = createscCATCH(data = geo_so@assays$SCT@counts, cluster = as.character(Idents(geo_so)))
# add marker genes to use for predictions
geo_catch@markergene = geo_markers# -------------------------------------------------------------------------
# specify tissues/cell-types from the scCATCH reference
tissues_of_interest = c('Blood', 'Peripheral Blood', 'Muscle', 'Skeletal muscle', 'Epidermis', 'Skin')
species_tissue_mask = cellmatch$species == 'Mouse' & cellmatch$tissue %in% tissues_of_interest
geo_catch@marker = cellmatch[species_tissue_mask, ]# -------------------------------------------------------------------------
# run scCATCH to generate predictions
geo_catch = findcelltype(geo_catch)
# look at the predictions
View(head(geo_catch@celltype))# -------------------------------------------------------------------------
# cleanup predictions
sc_pred_tbl = geo_catch@celltype %>%
select(cluster, cell_type, celltype_score) %>%
rename(cell_type_prediction = cell_type)
sc_pred_tbl| cluster | cell_type_prediction | celltype_score |
|---|---|---|
| 0 | Hematopoietic Stem Cell | 0.87 |
| 1 | Pericyte | 0.75 |
| 2 | Macrophage | 0.82 |
| 3 | Dendritic Cell | 0.86 |
| 4 | Monocyte | 0.82 |
| 5 | Hematopoietic Stem Cell | 0.92 |
| 6 | Muscle Progenitor Cell | 0.71 |
| 7 | Hematopoietic Stem Cell | 0.87 |
| 8 | Muscle Progenitor Cell | 0.75 |
| 9 | Muscle Satellite Cell | 0.93 |
| 10 | Hematopoietic Stem Cell | 0.9 |
| 11 | Dendritic Cell | 0.85 |
| 12 | Regulatory T Cell | 0.9 |
| 13 | Dendritic Cell | 0.85 |
| 14 | Dendritic Cell, Monocyte, Progenitor Cell | 0.71, 0.71, 0.71 |
| 15 | CD8+ T Cell | 0.88 |
| 16 | Stem Cell | 0.84 |
| 17 | Muscle Cell | 0.69 |
When we look at our results we can see the cell type score, which
gives us an idea of the confidence of that prediction. Not shown here
but the full celltype table also includes marker genes and
PMIDs for relevant literature for each prediction.
In our experience, these kinds of results often help guide cluster annotation but scores can vary and the predictions may need to be revised based on researcher’s knowledge of the biological system. As these cell-types correspond to the cell-types and subtypes we’d expect to be present in these data and most of the prediction scores are quite high, we can reasonably use these results to help annotate our clusters with some minor adjustments.
To revise the cluster annotation from those predicted by scCATCH, it can be helpful to output a table that can be edited in excel or a text editor.
# -------------------------------------------------------------------------
# Write scCATCH predictions to file
write_csv(sc_pred_tbl, file = 'results/tables/scCATCH_cluster_predictions.csv')Known cell-type markers
To confirm and/or refine the scCATCH predictions, we’ll spot check some known markers for immune populations. Then we’ll look look at some other key marker genes from some other relevant resources like Chen et al (2021), Buechler et al (2021) Roman (2023), Li et al (2022) and Nestorowa et al (2016) to see if other modifications should be made to the scCATCH predictions:
Immune marker genes
# -------------------------------------------------------------------------
# Create a **named list** of immune cells and associated gene markers
immune_markers = list(
'Inflam. Macrophage' = c('Cd14', 'Cxcl2'),
'Platelet' = c('Pf4'),
'Mast cells' = c('Gata2', 'Kit'),
'NK cells' = c('Nkg7', 'Klrd1'),
'B-cell'= c( 'Ly6d', 'Cd19', 'Cd79b', 'Ms4a1'),
'T-cell' = c( 'Cd3d','Cd3e','Cd3g')
)
immune_markers$`Inflam. Macrophage`
[1] "Cd14" "Cxcl2"
$Platelet
[1] "Pf4"
$`Mast cells`
[1] "Gata2" "Kit"
$`NK cells`
[1] "Nkg7" "Klrd1"
$`B-cell`
[1] "Ly6d" "Cd19" "Cd79b" "Ms4a1"
$`T-cell`
[1] "Cd3d" "Cd3e" "Cd3g"# -------------------------------------------------------------------------
# Make a dot plot of immune markers to refine cluster identification
# Since this dot plot is based on known markers instead of empirical markers,
# we'll cue that by using red instead of the default blue.
immune_markers_plot_basic = DotPlot(geo_so,
features = immune_markers,
assay = 'SCT',
cols = c("lightgrey", "darkred"))
immune_markers_plot_basic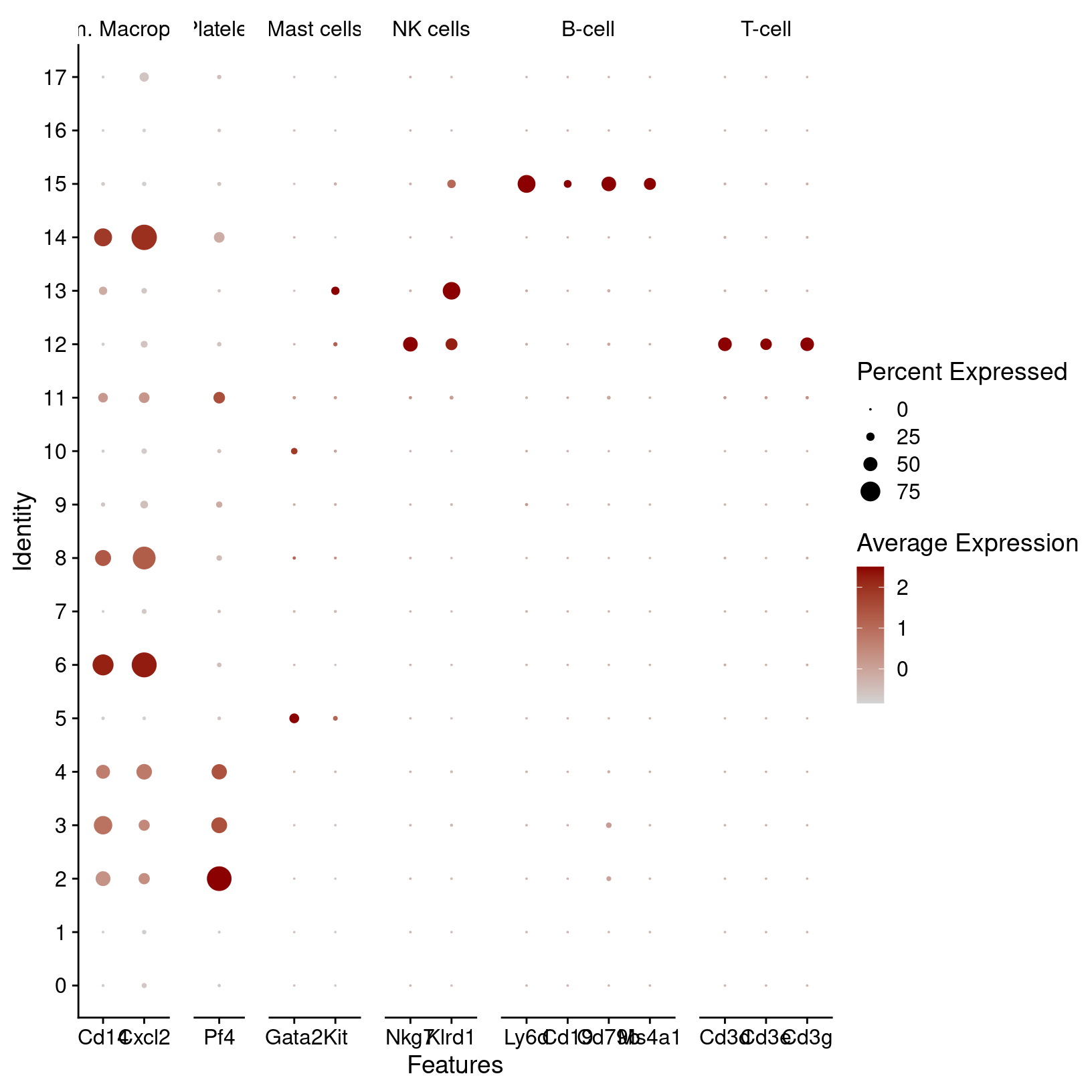
Dot plots show the gene expression patterns across clusters. This plot also groups the genes by their immune cell categories. It’s very nice - but the genes symbols (bottom) are overlapping and hard to read. Also the immune cell categories (top) are truncated. Since this is a ggplot object, we can adjust it to create a better plot:
# -------------------------------------------------------------------------
# Start with the plot above but reduce the font size and rotate the gene labels
immune_markers_plot_better = immune_markers_plot_basic +
theme(text=element_text(size=10),
axis.text.x = element_text(angle = 45, vjust = 0.5))
immune_markers_plot_better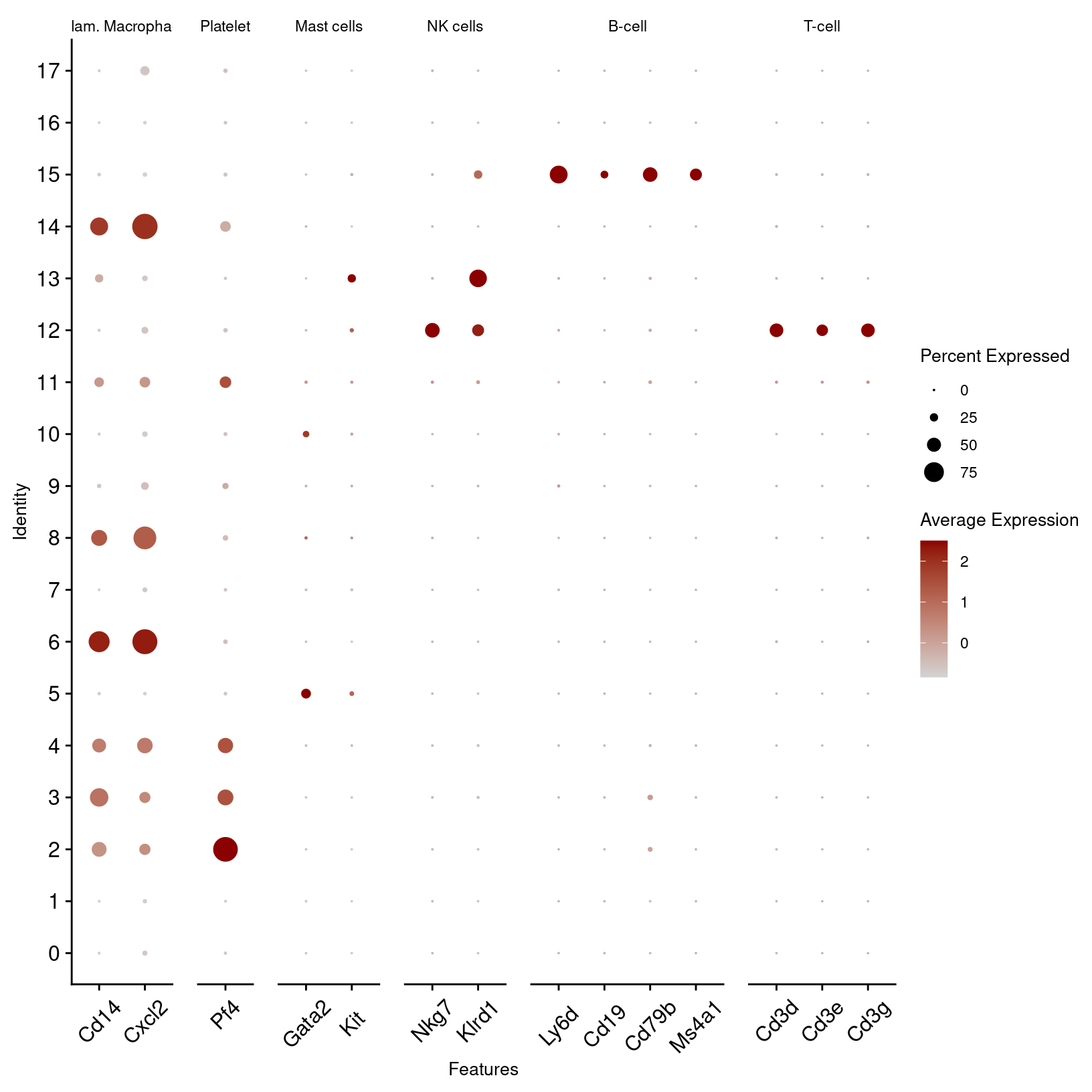
More readable than before - but with a few more ggplot functions, we can make it even better:
- coord_flip() rotates the plot
- facet_grid() adds space between the cell types
- theme() paramaters makes the cell type labels horizontal and to right the gene symbols
# -------------------------------------------------------------------------
# Continuing adjustments to plot above
immune_markers_plot_best = immune_markers_plot_better +
coord_flip() +
facet_grid(rows = vars(feature.groups),
scales = 'free',
space = 'free',
switch ='y') +
theme(strip.placement = 'outside',
strip.text.y.left = element_text(angle = 0))
immune_markers_plot_best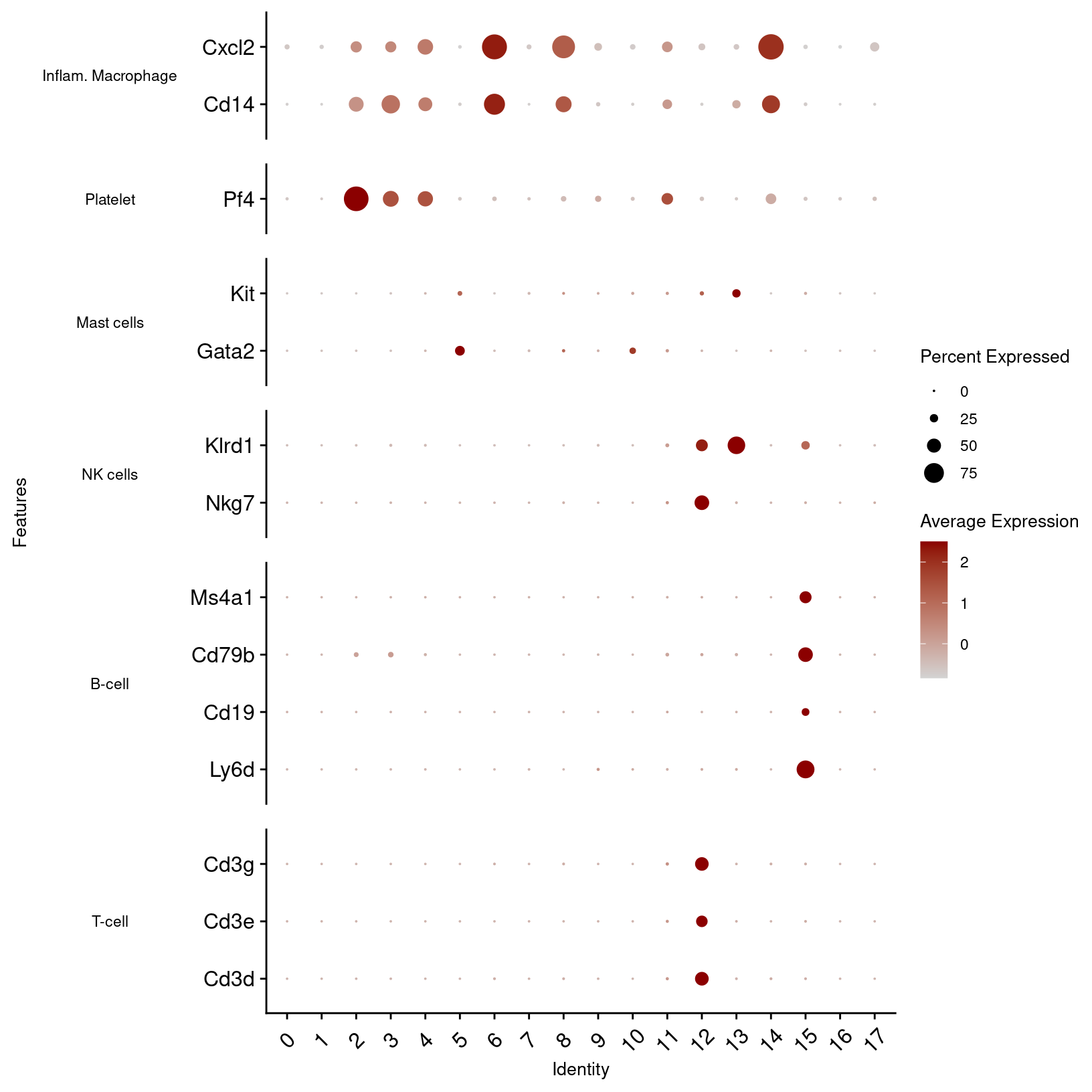
# -------------------------------------------------------------------------
# save dot plot to file
ggsave(filename = 'results/figures/immune_markers_sct_dot_plot.png',
plot = immune_markers_plot_best,
width = 10, height = 5, units = 'in')Other marker genes
# -------------------------------------------------------------------------
# Create a nested list of other cells and associated gene markers
other_markers = list(
'Pericyte' = c('Acan', 'Sox9'),
'SMC' = c('Acta2', 'Myh11'), #mesenchymal smooth-muscle cell/mesenchymal lineage
'Keratinocytes' = c('Thy1', 'Dlk1'), #fibro progenitors
'Myofibroblasts' = c('Tmem100', 'Cd34', 'Ly6c1'), #hematopoetic stem/activated fibroblast
'Fibroblast' = c('Dpt','Fn1','Col3a1'), #activated fib
'Endothelial' = c('Pecam1','Cd38'), #from wound healing; Pecam1 also exp in endothelial
'HSC' = c('Ltb','Cd74'), #less well defined/conflicting definitions
'Erythroid' = c('Hba-a1')
)
other_markers$Pericyte
[1] "Acan" "Sox9"
$SMC
[1] "Acta2" "Myh11"
$Keratinocytes
[1] "Thy1" "Dlk1"
$Myofibroblasts
[1] "Tmem100" "Cd34" "Ly6c1"
$Fibroblast
[1] "Dpt" "Fn1" "Col3a1"
$Endothelial
[1] "Pecam1" "Cd38"
$HSC
[1] "Ltb" "Cd74"
$Erythroid
[1] "Hba-a1"# -------------------------------------------------------------------------
# Plot known cell-type markers
other_markers_dot_plot_basic = DotPlot(geo_so,
features = other_markers,
assay = 'SCT',
cols = c("lightgrey", "darkred")) +
theme(text=element_text(size=10), axis.text.x = element_text(angle = 45, vjust = 0.5))
other_markers_dot_plot_basic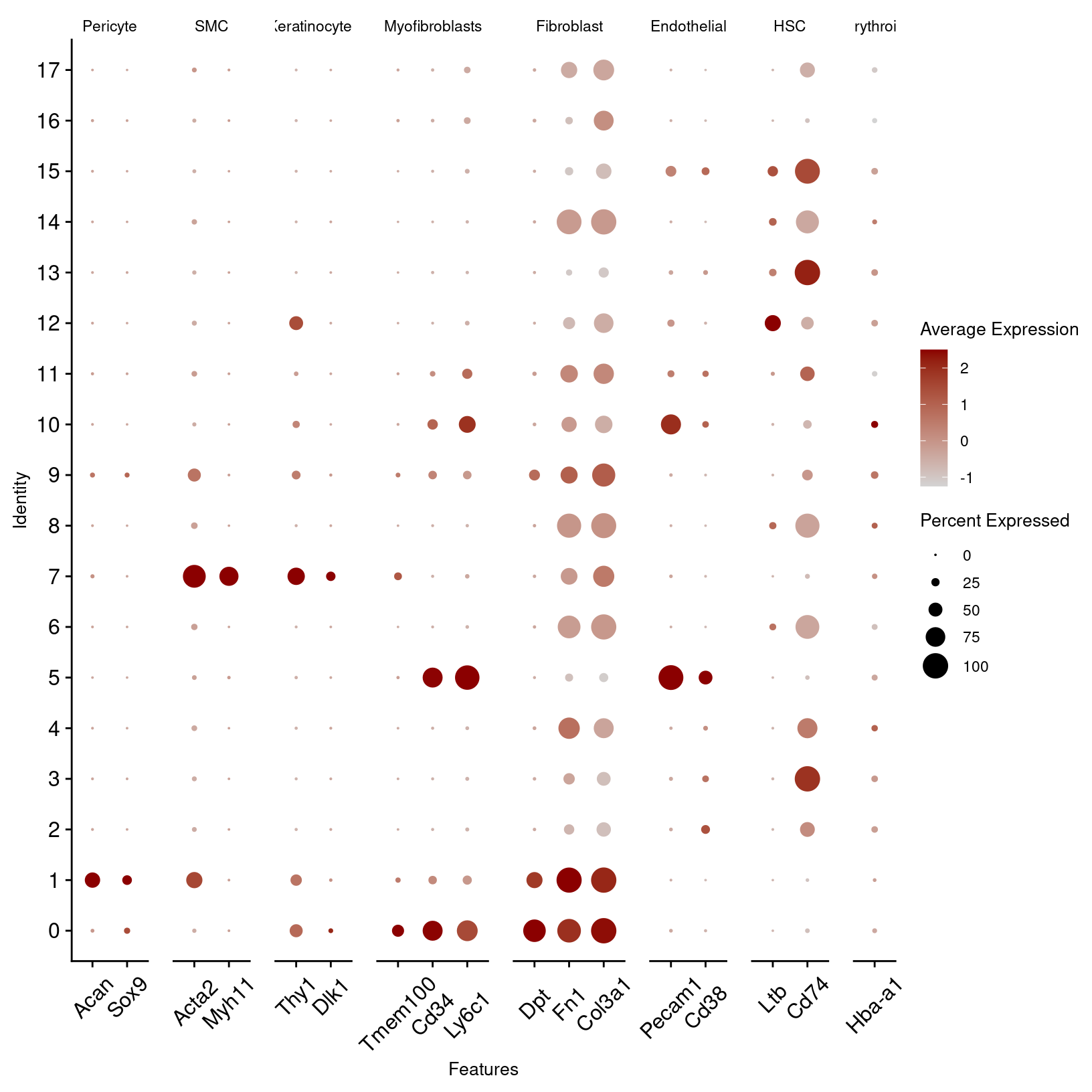
# -------------------------------------------------------------------------
# Enhance plot aesthetics as we did above
other_markers_dot_plot = other_markers_dot_plot_basic +
theme(text=element_text(size=10),
axis.text.x = element_text(angle = 45, vjust = 0.5)) +
coord_flip() +
facet_grid(rows = vars(feature.groups),
scales = 'free',
space = 'free',
switch ='y') +
theme(strip.placement = 'outside',
strip.text.y.left = element_text(angle = 0))
other_markers_dot_plot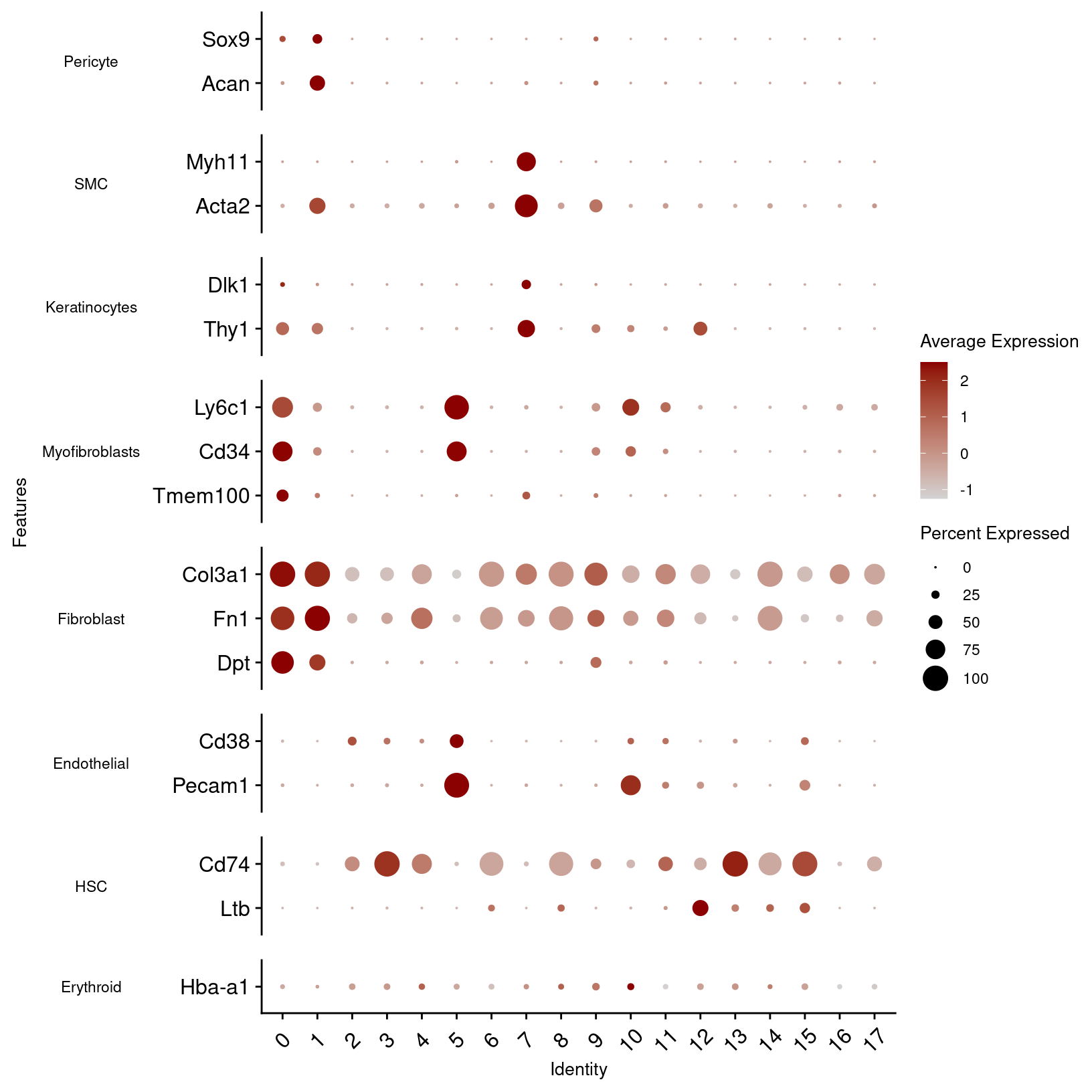
# -------------------------------------------------------------------------
# Save other markers dot plot to file
ggsave(filename = 'results/figures/other_markers_sct_dot_plot.png',
plot = other_markers_dot_plot, width = 12, height = 5, units = 'in')In the first plot, B-cell and T-cell markers seem to line up with the predictions and are limited to single clusters. However, macrophage and dendrocyte markers match to multiple clusters including some annotated with different cell types, so we can consider modifying those cluster labels.
From the other marker genes, the patterns are less clear so we may want to test other clustering parameters and discuss the results with a researcher familiar with the expected cell types. However, we can notice some patterns that we can use to refine our cluster annotations.
Markers from source paper
Plotting the expression of genes of interest from Sorkin, Huber et al
Often we have prior information about what cell types are expected in
our samples and key marker genes for those populations. This can be an
important part of evaluating our clusters, since if genes that are known
markers for a specific cell type are found in too many or too few
clusters as that can suggest that re-clustering is needed or that some
of the clusters should be manually combined before annotating. We can
create lists of markers used in figures from the original paper before using the same
DotPlot() function to visualize the expression level and
frequency of these genes in our current clusters:
# -------------------------------------------------------------------------
# Create lists of genes from paper
# https://pmc.ncbi.nlm.nih.gov/articles/PMC7002453/#Fig1
fig1g_markers = c('Cxcl1', 'Cxcl2', 'Ccl2', 'Ccl3', 'Ccl4', 'Il1b', 'Il6', 'Tnf', 'Tgfb1', 'Tgfb2', 'Tgfb3', 'Cxcl5')
fig1h_markers = c('Cxcr2', 'Csf1r', 'Csf3r', 'Tgfbr1', 'Tgfbr3', 'Il1r1', 'Il6ra', 'Lifr', 'Tgfbr2')
# It's diligent to verify genes from paper were measured in the data.
markers_from_paper = unique(c(fig1g_markers, fig1h_markers))
measured_genes = Features(geo_so[["SCT"]])
# If everything worked, missing markers *should be* empty. If it's not empty, we
# could examine the marker symbols to see if we mistyped a symbol or if the
# marker was named something other than the canonical gene symbol in the paper.
missing_markers = setdiff(markers_from_paper, measured_genes)
cat(paste0(length(missing_markers),
' gene(s) were listed as markers but not found in the data. Excerpt below:'))0 gene(s) were listed as markers but not found in the data. Excerpt below:head(missing_markers)character(0)# -------------------------------------------------------------------------
# create DotPlots for genes from paper
fig1g_sct_dot_plot = DotPlot(geo_so,
features = fig1g_markers,
assay = 'SCT',
cols = c("lightgrey", "darkred"))
fig1h_sct_dot_plot = DotPlot(geo_so,
features = fig1h_markers,
assay = 'SCT',
cols = c("lightgrey", "darkred"))
fig1g_sct_dot_plot
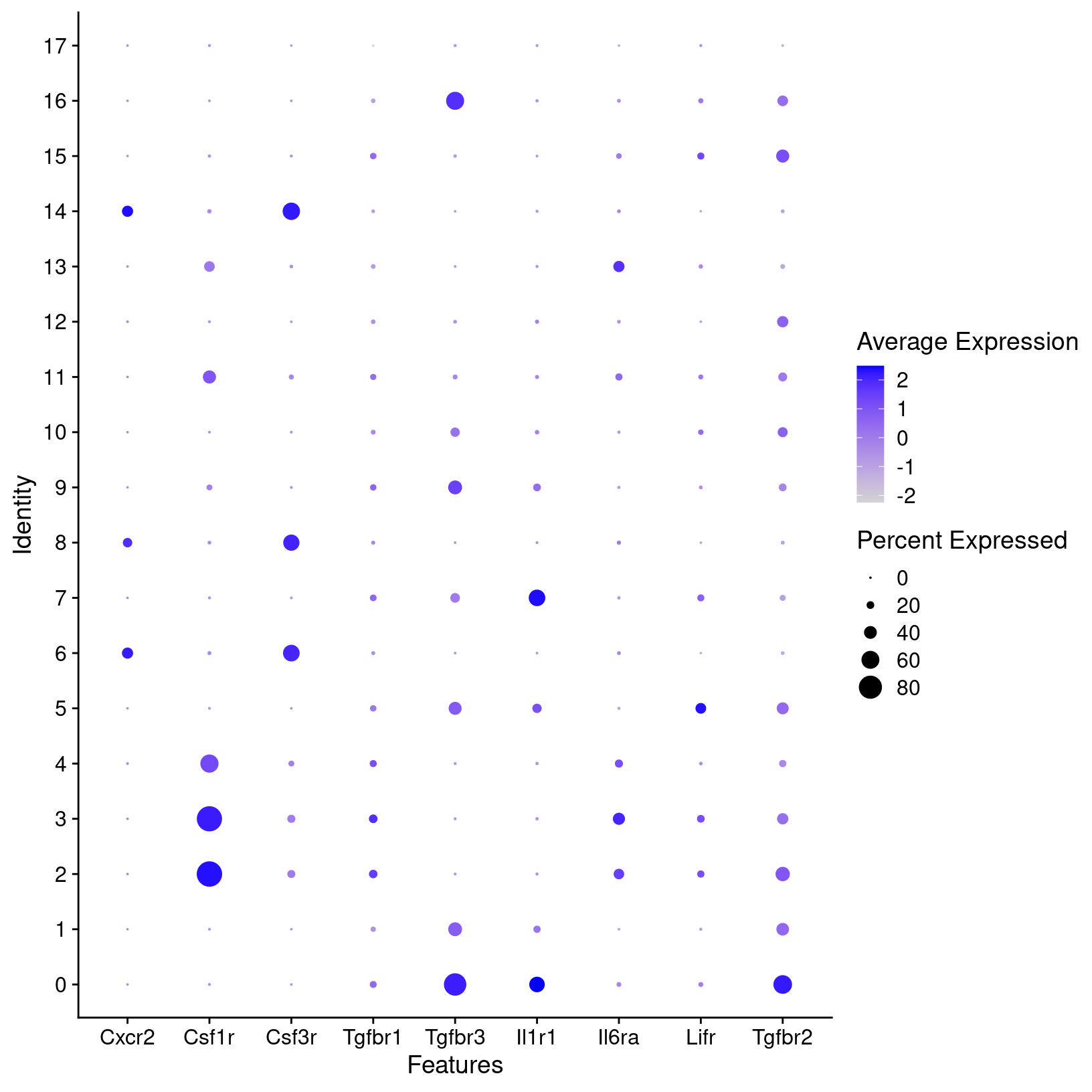
fig1h_sct_dot_plot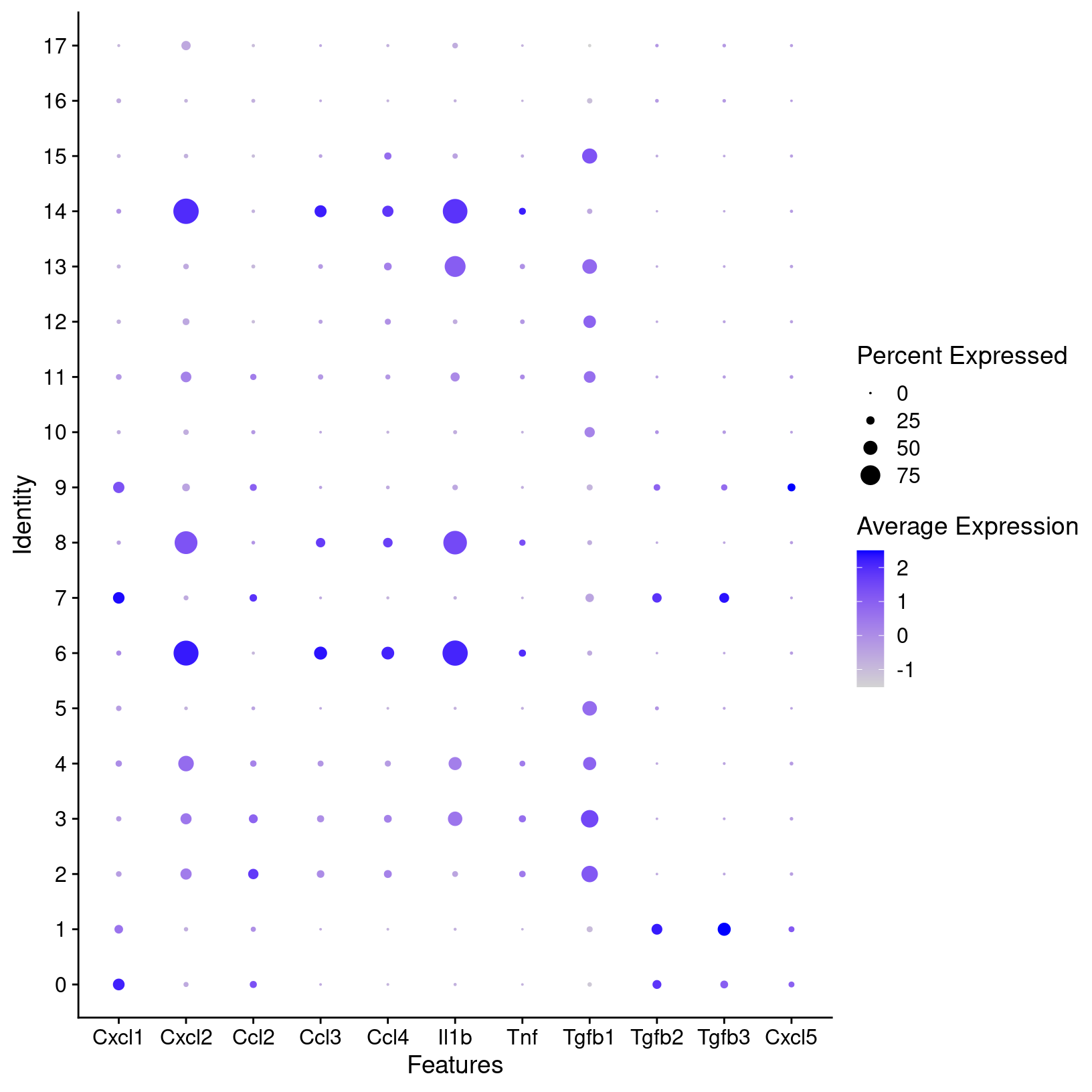
# -------------------------------------------------------------------------
# save plots to file
ggsave(filename = 'results/figures/markers_fig1g_sct_dot_plot.png',
plot = fig1g_sct_dot_plot, width = 8, height = 6, units = 'in')
ggsave(filename = 'results/figures/markers_fig1h_sct_dot_plot.png',
plot = fig1h_sct_dot_plot, width = 8, height = 6, units = 'in')For known marker genes, it’s important to note that since scRNA-seq is only measuring transcriptional signals that markers at the protein level (e.g used for approaches like FACS) may be less effective. An alternative or complement to using marker genes could be methods like using gene set enrichment (GSEA) as demonstrated in the OSCA book to aid in annotations. However, the book “Best practices for single-cell analysis across modalities” by Heumos, Schaar, Lance, et al. points out that “it is often useful to work together with experts … [like a] biologist who has more extensive knowledge of the tissue, the biology, the expected cell types and markers etc.”. In our experience, we find that experience and knowledge of the researchers we work with is invaluable.
Refine and label clusters
Next, we’ll use a revised version of the cell type predictions from a file that we prepared by refining the scCATCH predictions. How is a table like this created?
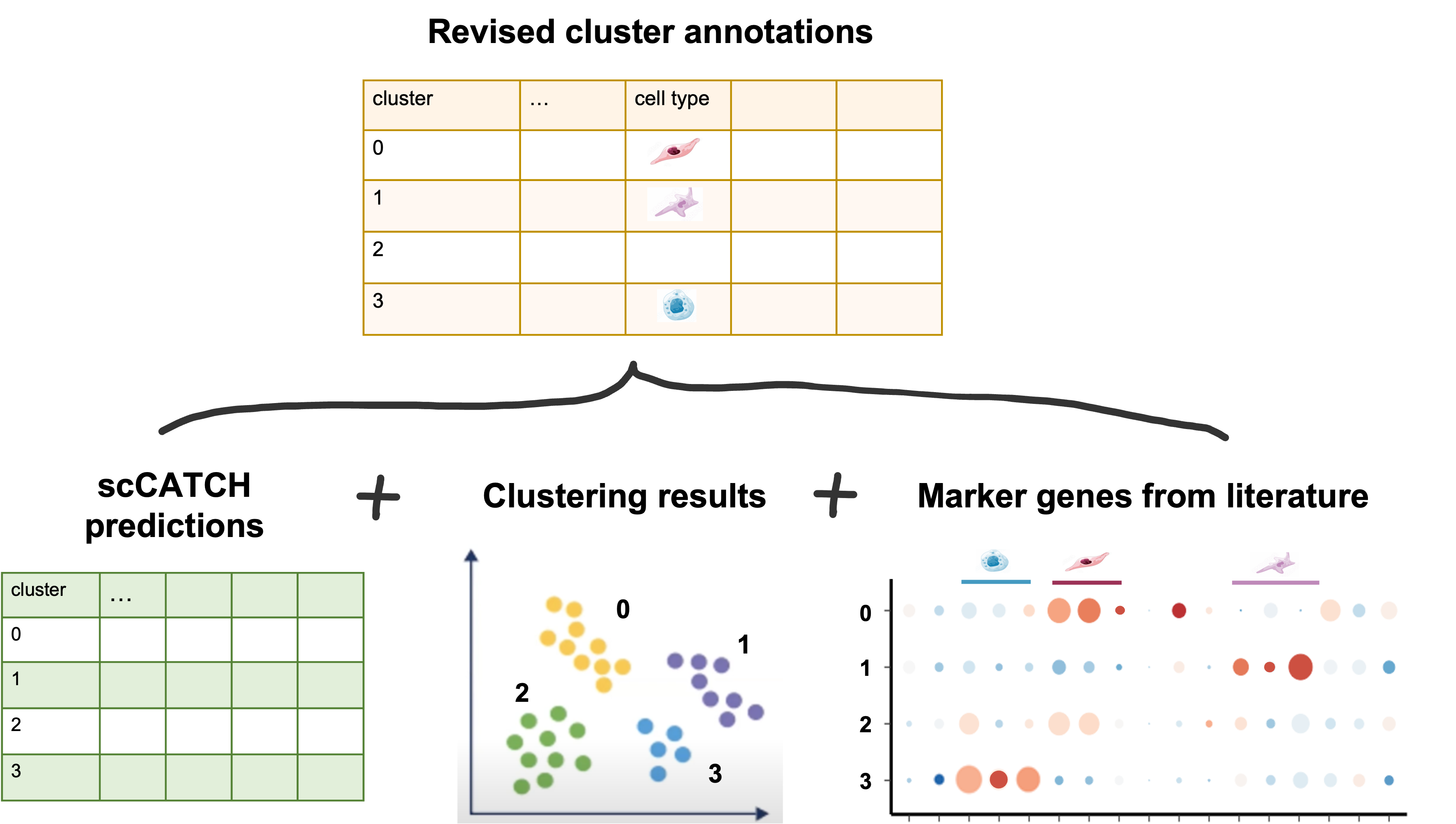
Note: To add the cell-type labels to our Seurat object to replace our clusters’ numerical identities, we will create a new metadata object to join in the cell type labels. However this will destroy the row names, which will cause a problem in Seurat so we have to add them back.
Load a pre-prepared file:
# -------------------------------------------------------------------------
# Load the revised annotations from prepared file
celltype_annos = read_csv('inputs/prepared_data/revised_cluster_annotations.csv') %>%
mutate(cluster=factor(cluster))
head(celltype_annos)# -------------------------------------------------------------------------
# Merge cell types in but as a new table to slide into @meta.data
copy_metadata = geo_so@meta.data
new_metadata = copy_metadata %>%
left_join(celltype_annos, by = c('integrated.sct.rpca.clusters' = 'cluster'))
# We are implicitly relying on the same row order!
rownames(new_metadata) = rownames(geo_so@meta.data)
# Replace the meta.data
geo_so@meta.data = new_metadata
View(head(geo_so@meta.data))| orig.ident | nCount_RNA | nFeature_RNA | condition | time | replicate | percent.mt | nCount_SCT | nFeature_SCT | integrated.sct.rpca.clusters | seurat_clusters | cell_type_prediction | celltype_score | cell_type | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| HODay0replicate1_AAACCTGAGAGAACAG-1 | HODay0replicate1 | 10234 | 3226 | HO | Day0 | replicate1 | 1.240962 | 6062 | 2867 | 0 | 3 | Hematopoietic Stem Cell | 0.87 | Myofibroblast |
| HODay0replicate1_AAACCTGGTCATGCAT-1 | HODay0replicate1 | 3158 | 1499 | HO | Day0 | replicate1 | 7.536416 | 4607 | 1509 | 0 | 3 | Hematopoietic Stem Cell | 0.87 | Myofibroblast |
| HODay0replicate1_AAACCTGTCAGAGCTT-1 | HODay0replicate1 | 13464 | 4102 | HO | Day0 | replicate1 | 3.112002 | 5314 | 2370 | 0 | 3 | Hematopoietic Stem Cell | 0.87 | Myofibroblast |
| HODay0replicate1_AAACGGGAGAGACTTA-1 | HODay0replicate1 | 577 | 346 | HO | Day0 | replicate1 | 1.559792 | 3877 | 1031 | 11 | 9 | Dendritic Cell | 0.85 | Hematopoietic Stem Cell |
| HODay0replicate1_AAACGGGAGGCCCGTT-1 | HODay0replicate1 | 1189 | 629 | HO | Day0 | replicate1 | 3.700589 | 4166 | 915 | 0 | 3 | Hematopoietic Stem Cell | 0.87 | Myofibroblast |
| HODay0replicate1_AAACGGGCAACTGGCC-1 | HODay0replicate1 | 7726 | 2602 | HO | Day0 | replicate1 | 2.938131 | 5865 | 2588 | 0 | 3 | Hematopoietic Stem Cell | 0.87 | Myofibroblast |
Checkpoint : Has the metadata for your
geo_so object been updated?
Visualise annotated clusters
Lastly, we can generate a revised UMAP plot with our descriptive
cluster labels by using our updated Seurat object and providing the new
cell_type label for the group.by argument:
# -------------------------------------------------------------------------
# Make a labeled UMAP plot of clusters
annos_umap_plot =
DimPlot(geo_so, group.by = 'cell_type', label = TRUE, reduction = 'umap.integrated.sct.rpca')
annos_umap_plot
ggsave(filename = 'results/figures/umap_integrated_annotated.png',
plot = annos_umap_plot,
width = 8, height = 6, units = 'in')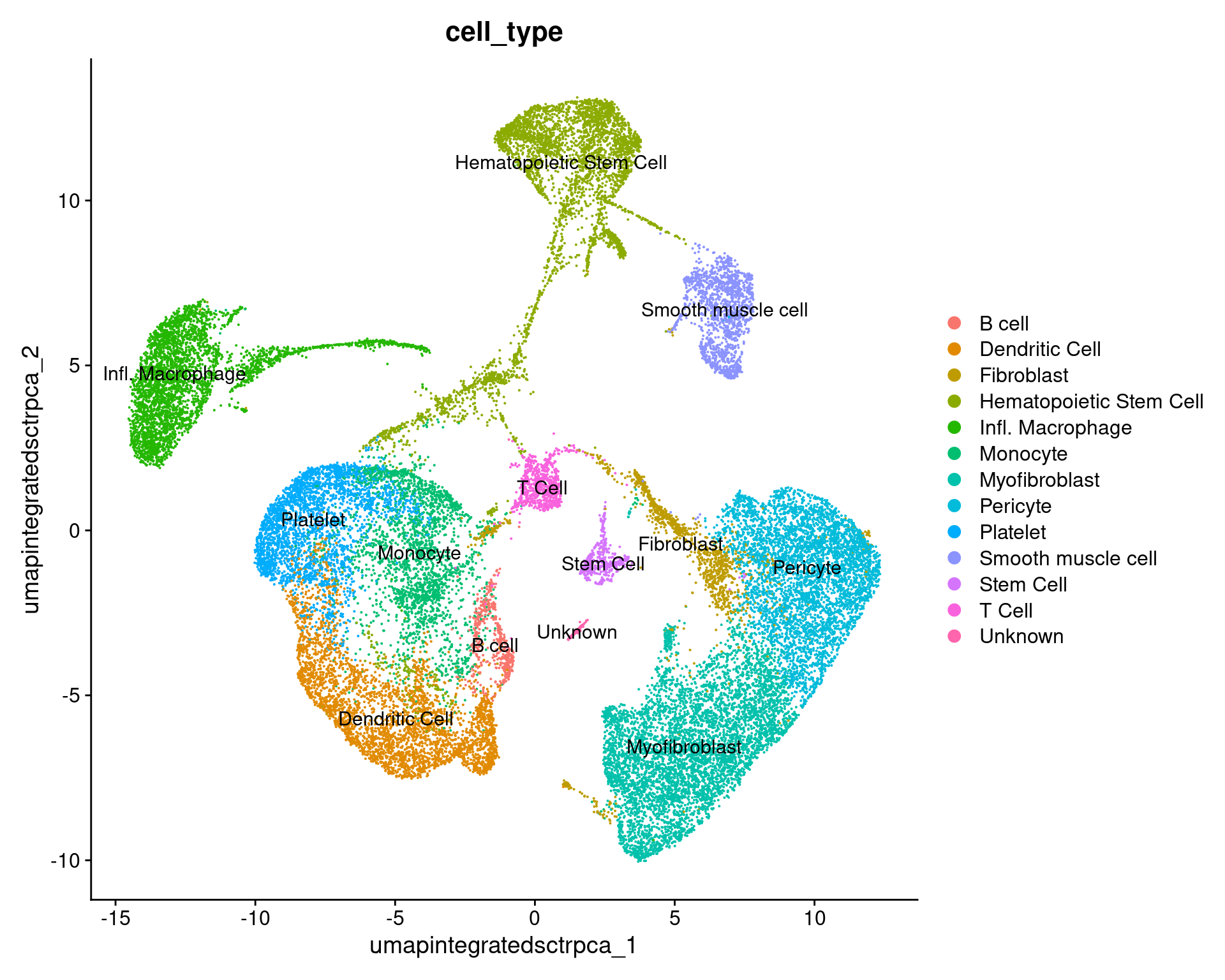
# -------------------------------------------------------------------------
# Repeat, splitting by day
annos_umap_condition_plot =
DimPlot(geo_so,
group.by = 'cell_type',
split.by = 'time',
label = FALSE,
reduction = 'umap.integrated.sct.rpca')
annos_umap_condition_plot
ggsave(filename = 'results/figures/umap_integrated_annotated_byCondition.png',
plot = annos_umap_condition_plot,
width = 14, height = 5, units = 'in')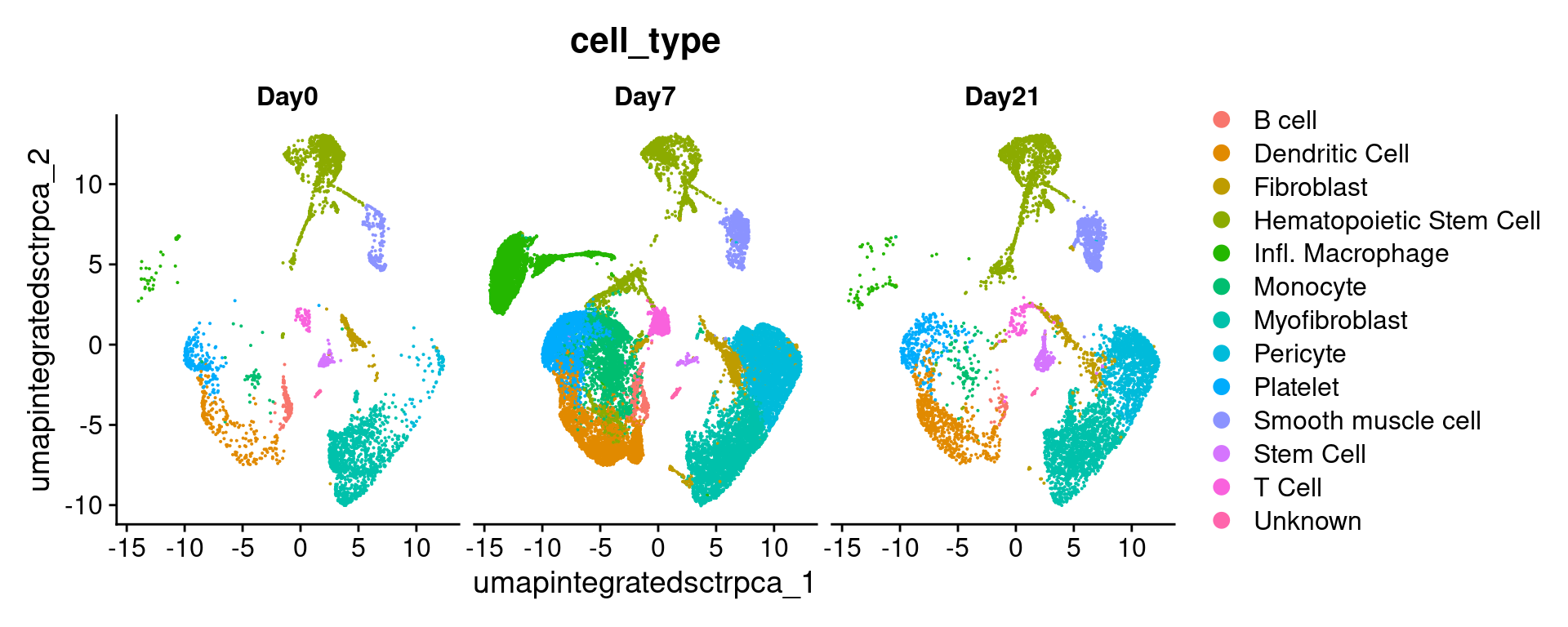
It can also be helpful to compare our annotated UMAP to the original clustering results:
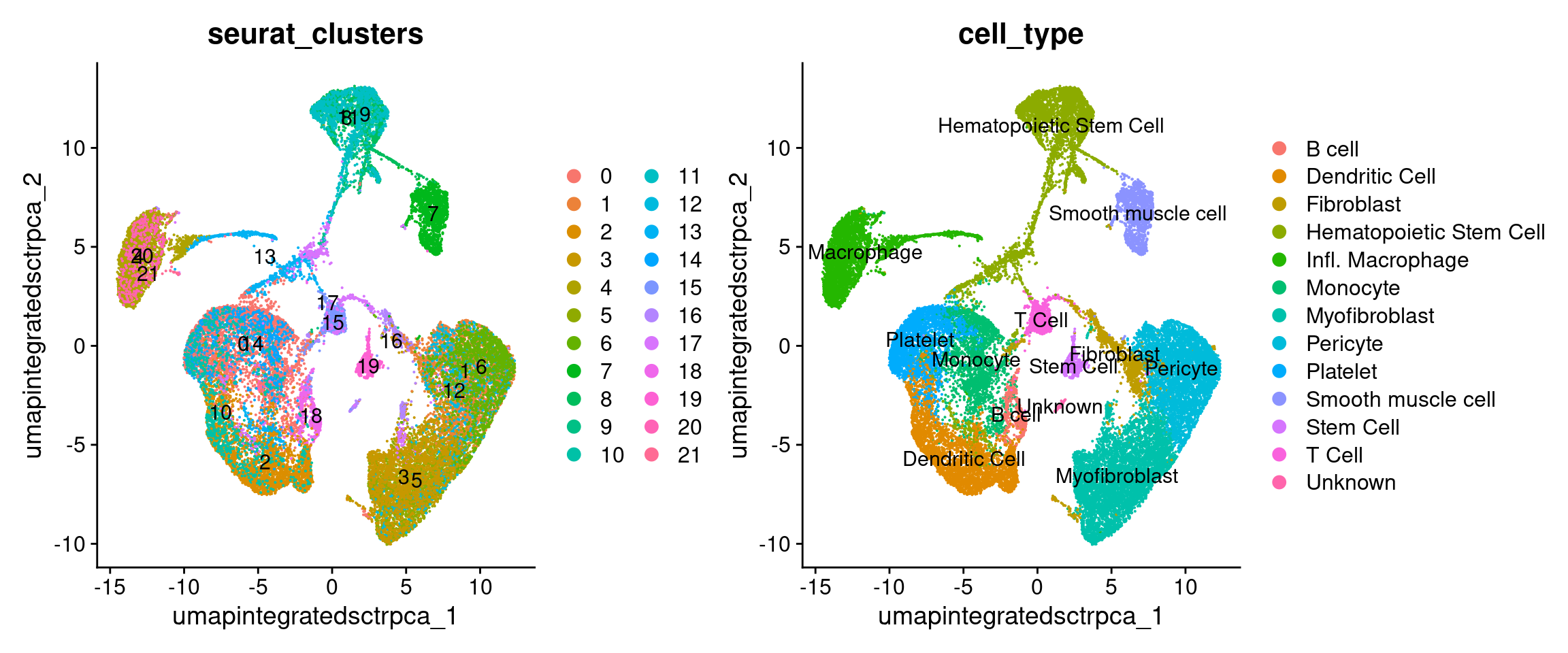
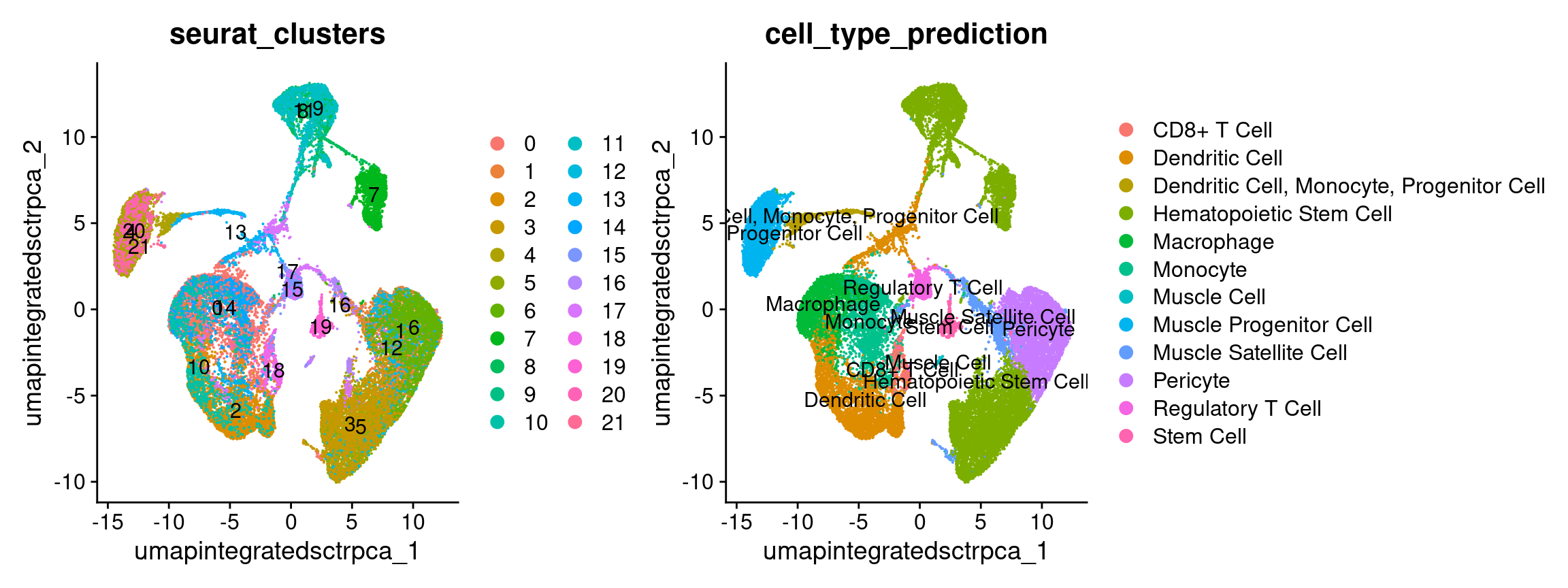
Why didn’t we just use the original scCATCH labels? (with code)
Predictive tools can be useful but the labels produced may not match
the level of specificity that’s relevant to your biological
question or use the same labels for clusters that don’t seems to share
similar expression programs
used (Mb) gc trigger (Mb) max used (Mb)
Ncells 6929089 370.1 12351778 659.7 12351778 659.7
Vcells 339445783 2589.8 795005255 6065.5 792577216 6046.9
Save our progress
# -------------------------------------------------------------------------
# Discard all ggplot objects currently in environment
# (Ok since we saved the plots as we went along)
rm(list=names(which(unlist(eapply(.GlobalEnv, is.ggplot)))));
gc() used (Mb) gc trigger (Mb) max used (Mb)
Ncells 6885314 367.8 12351778 659.7 12351778 659.7
Vcells 336752638 2569.3 795005255 6065.5 792577216 6046.9We’ll save the scCATCH object and our updated Seurat object with cell type annotations.
# -------------------------------------------------------------------------
# Save Seurat object and annotations
saveRDS(geo_so, file = 'results/rdata/geo_so_sct_integrated_with_annos.rds')
saveRDS(geo_catch, file = 'results/rdata/geo_catch.rds')
Summary
|
|
| Starting with clustered data, we can summarize and compare gene expression for known gene markers within each cluster, irrespective of sample or condition, to help label clusters with the appropriate cell-type or subtype. |
In this section we:
- Used
scCATCHto generate predicted cell-type annotations for our initial clusters
- Plotted the expression per cluster of known markers to confirm and
refine the predictions
- Finalized cell type labels for our clusters
Next steps: Differential Expression
These materials have been adapted and extended from materials listed above. These are open access materials distributed under the terms of the Creative Commons Attribution license (CC BY 4.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
| Previous lesson | Top of this lesson | Next lesson |
|---|